Der Webseiten Basis Sicherheit Guide
Jeder von uns ruft täglich diverse Webseiten auf. Wir benutzen sie um Informationen zu sammeln, Dinge zu kaufen, uns mit anderen auszutauschen und vieles mehr. Das Schöne daran ist, dass wir dabei weltweit auf diese Webseiten zugreifen können. Die Google Suche ist nicht nur für die Einwohner von Mountain View erreichbar, sondern für jeden mit einer Internetverbindung und einem internetfähigen Gerät. Und auch der kleinste Onlineshop kann seine Waren in die ganze Welt liefern.
Durch diese weltweite Erreichbarkeit entsteht für Webseiten Betreiber allerdings auch ein großes Risiko. Ihre Seite ist nicht nur weltweit erreichbar, sondern auch weltweit angreifbar. Vom professionellen Cyberkriminellen bis hin zum gelangweilten Teenager, jeder kann zu jeder Zeit versuchen Ihre Webseiten zu hacken. Da viele Webseiten darüber hinaus auch noch persönliche Daten und Zahlungsinformationen verarbeiten, stellen sie interessante Ziele dar.
Umso wichtiger ist es, Webseiten bestmöglich gegen Angriffe abzusichern, bzw. Maßnahmen zu treffen, die im Worst Case eines erfolgreichen Hacks greifen können. Aus diesem Grund haben wir diesen Webseiten Basis Sicherheit Guide verfasst, der Ihnen einige Tipps an die Hand gibt, wie Sie Ihre Webseiten sicherer machen können. Darüber hinaus können Sie eine Kurzversion dieses Guides auch als praktische Checkliste herunterladen um die einzelnen Punkte mit Ihren Entwicklern abzuhaken.
User Input überprüfen
Ohne Interaktion seitens der User wären viele Webseiten überhaupt nicht denkbar. Welchen Sinn hätte Facebook, wenn man seinen Freunden keine Nachrichten schicken könnte? Würde man noch genauso viele Sachen kaufen, wenn man bei Amazon keine Bewertungen anderer User lesen könnte? Wie würde man Dinge suchen, wenn nicht über Google?
All diese Seiten sind erst dadurch wirklich sinnvoll, dass ich als User etwas eingeben kann. Gleichzeitig ist eine User Eingabe, die von der Webseite verarbeitet wird, natürlich auch ein ziemliches Sicherheitsrisiko. Viele Schwachstellen wie Cross Site Scripting (XSS) oder SQL Injection, lassen sich darauf zurückführen, dass User Input nicht korrekt verarbeitet wird.
Die korrekte Validierung von User Input stellt deshalb eine der wichtigsten Maßnahmen dar und sollte auf jeder Webseite umgesetzt werden.
Beispiele für Funktionen, an denen User Eingaben machen können, die von der Webseite verarbeitet werden sind etwa:
- Registrierungs- und Login Seiten
- Kommentarfunktionen
- Suchfelder
- Signaturen/Status (in Foren)
- Profil Einstellungen
- Rezensionen/Reviews
Was passiert, wenn User Input nicht korrekt gefiltert wird, kann bei einer Testanwendung von Google ausprobiert werden:

Die Anwendung ist der Google Suche nachempfunden. Entsprechend kann man dann auch eine Suchanfrage eingeben. Zunächst probieren wir „Test“ aus, um zu sehen, wie sich die Anwendung verhält.

Suchergebnisse werden nicht gefunden, dafür wird uns die Eingabe „Test“ wieder angezeigt, der Server spiegelt also unseren Input. Jetzt können wir versuchen, ob man auch etwas anderes als Buchstaben eingeben kann: Der typische Test auf XSS Schwachstellen ist die Eingabe von <script>alert(„XSS“)</script> Dieses simple JavaScript Skript erzeugt eine Standard Alert Box mit dem Inhalt XSS. Wird die Box angezeigt, ist die Anwendung anfällig für XSS.

Wie im Screenshot zu sehen, wird der JavaScript Code tatsächlich ausgeführt. Wir haben dem Server JavaScript Code als Input gegeben, der Server hat diesen Code in die Ergebnisseite eingebettet und als unser Browser die Ergebnisseite geladen hat, wurde der Code ausgeführt.
Im konkreten Fall ist die Schwachstelle nicht hochdramatisch, weil sie nur funktioniert, wenn der User den JavaScript Code aktiv eingibt (Self XSS). Ein möglicher Angreifer wird im nächsten Schritt allerdings versuchen, das Ausführen von Code auch über einen Link zu ermöglichen. Das ist dann möglich, wenn die Suchanfrage Teil der URL ist, etwa www.beispiel.de/search=<script>alert(„XSS“)</script> . Ist das der Fall, kann der Angreifer den entsprechenden Link an mögliche Opfer verschicken, klicken diese darauf, gelangen sie zur Ergebnisseite und der JavaScript Code wird ausgeführt (Reflected XSS). Statt eine Alert Box könnte der Code beispielsweise die Session ID eines Users auslesen und an den Angreifer senden, sodass dieser die Session übernehmen kann.
Die größten Auswirkungen hat eine solche Schwachstelle, wenn der User Input gespeichert wird und auch für andere User zugänglich ist (Stored XSS). Das ist etwa in Foren problematisch oder bei den Bewertungsfunktionen von Onlineshops. Wenn ein User als Signatur statt Text JavaScript Code eingibt und dieser Code von der Anwendung nicht gefiltert wird, wird der Code jedes Mal ausgeführt, wenn ein anderer User einen Beitrag aufruft, bei dem der Angreifer kommentiert und somit seine Signatur hinterlassen hat.
Ok, nun wissen wir wie es funktioniert, aber was kann man dagegen machen?
Zunächst sollte versucht werden, User Input soweit wie möglich einzuschränken. Wenn bei der Registrierung etwa das Alter abgefragt wird, sollte dafür kein Freitextfeld verwendet werden, sondern ein Input Feld bei dem der User Tag, Monat und Jahr seines Geburtstages anklicken kann. Neben der Tatsache, dass dadurch potenziell bösartiger Input verhindert wird, wird durch diese Vereinheitlichung auch die weitere Verarbeitung erleichtert. Bei einem Freitext Feld wären ansonsten viele verschiedene Variationen möglich: 04.03.2000, 4.3.2000, 4. März 2000, Vierter 3. 2000 etc. Die Auswahl aus vordefinierten Werten sorgt dagegen dafür, dass die Form immer gleich ist und entsprechend leicht vom Server verarbeitet werden kann.
Logischerweise kann User Input nicht an allen Stellen auf diese Weise beschränkt werden. Eine Suchfunktion würde ihren Sinn etwa komplett verlieren, wenn sie nur eine bestimmte Anzahl an vordefinierten Suchbegriffen zulassen würde. Nachdem also im ersten Schritt alle Input Felder abgeändert wurden, bei denen Freitext nicht zwingend erforderlich ist, brauchen wir nun eine Lösung für Input Felder, bei denen kein Input vordefiniert werden kann.
Dafür muss der Input gefiltert werden. In einer Suchfunktion werden etwa Wörter, Zahlen und vielleicht bestimmte Suchoperatoren wie „+“, „:“ oder „““„ eingegeben. Andere Zeichen, insbesondere die <script> Tags sollten dagegen ausgefiltert werden, damit kein Ausführen von Code möglich ist.
Allerdings gibt es auch diverse Möglichkeiten, diese Zeichen zu codieren, sodass noch weitere Möglichkeiten genutzt werden sollten. Zunächst sollten so wenig User Eingaben wie möglich vom Server gespiegelt werden. Auf der Ergebnisseite einer Suche muss nicht zwangsläufig der verwendete Suchbegriff angezeigt werden, der User weiß schließlich, wonach er gesucht hat. Außerdem sollten Eingaben von Usern nicht Teil der URL sein. Und last but not least ist natürlich auch immer dann besondere Vorsicht gefragt, wenn es Teile der Anwendung gibt, in denen User Input gespeichert wird und dieser Input auch für andere zugänglich ist (Beiträge, Kommentare, Signaturen etc.). Bevor solche Funktionalitäten öffentlich zugänglich gemacht werden, sollten sie gründlich auf mögliche Schwachstellen getestet werden. Idealerweise nicht vom Entwicklerteam selbst, sondern von organisatorisch unabhängigen Dritten.
Besonders problematisch ist User Input auch dann, wenn das entsprechende Eingabefeld mit einer Datenbank verknüpft ist. Das kann beispielsweise bei einer Produktsuche der Fall sein. Statt JavaScript Code könnte der Angreifer in diesem Fall versuchen, SQL Statements einzugeben und auf diese Weise unerlaubt auf die Datenbank zuzugreifen, etwa um sich User Daten ausgeben zu lassen (SQL Injection). SQL Injections sind typischerweise etwas schwerer zu erreichen, dafür sind die potenziellen Auswirkungen in der Regel schwerwiegender als bei XSS.
Als Gegenmaßnahme können „vorgefertigte Datenbankabfragen“ (parameterized query) verwendet werden. Dabei wird die SQL Abfrage im Voraus kompiliert und anschließend können nur noch Werte für Variablen eingesetzt werden.
File Uploads überprüfen
Webseiten wie Instagram oder YouTube wären ohne den Content ihrer User kaum denkbar. Und auch viele B2B Anwendungen werden erst durch Upload Funktionalitäten wirklich sinnvoll.
Aus Sicht der IT-Sicherheit sind Uploads aber ein heikles Thema. Immerhin werden dabei Dateien auf den Server geladen und von diesem eventuell auch noch verarbeitet. Ist diese Funktionalität nicht abgesichert, stellt das praktisch ein offenes Einfallstor für Angreifer dar. Im „besten“ Fall kann der Angreifer durch einen Upload, den der Server nicht verarbeiten kann, einen Crash herbeiführen und die Stabilität der Anwendung gefährden. Das ist zwar ärgerlich (und im Falle großer Onlineshops, mit tausenden Transaktionen pro Minute, auch teuer) aber in der Regel noch nicht dramatisch.
Anders sieht es aus, wenn es dem Angreifer etwa gelingt, eigenen Code auf den Server zu laden und diesen auch noch zur Ausführung zu bringen. Kann er auf diese Weise etwa eine Shell erlangen, sind seinen Möglichkeiten kaum Grenzen gesetzt. Beispielsweise könnte er Userdaten wie Passwort Hashes herunterladen, um sie offline zu cracken. Mit entsprechenden Tools können auf diese Weise tausenden Hashes pro Sekunde überprüft werden, sodass es schnell zu einer Vielzahl kompromittierter User Konten kommen wird.
Aus diesem Grund muss jede Stelle, an der User Dateien in die Anwendung hochladen können, doppelt und dreifach abgesichert sein.
Beispiele für File Uploads auf Webseiten sind beispielsweise:
- Profilbilder
- Seitenspezifische Files (z.B. Videos auf einer Videoplattform)
- Rechnungen/Lieferscheine o.ä. (auf B2B Webseiten)
Um File Uploads abzusichern, sollte man sich zunächst überlegen, welche Dateien ein User hochladen soll. Für ein Profilbild können das etwa .png und .jpg sein. Anschließend verbietet man die nicht erlaubten Dateitypen. Dafür gibt es zwei Möglichkeiten: Blacklisting und Whitelisting. Beim Blacklisting wird explizit definiert was verboten ist: Im Falle eines Profilbilds etwa alle Code Files (.py, .php etc.), alle Dokumente (.docx, .xlsx etc.) und so weiter. Man merkt schon, wo hier das Problem liegt: Alle Dateitypen auszuschließen ist fast nicht möglich. Immerhin gibt es tausende davon, manche extrem weit verbreitet, andere nur in ganz bestimmten Nischen. Manche Open Source, andere proprietär, manche potenziell gefährlich, andere nicht. Hier alles korrekt zu definieren ist ein Ding der Unmöglichkeit, zumal die Liste in regelmäßigen Abständen auch angepasst werden müsste um neue Dateitypen aufzunehmen.
Wesentlich komfortabler ist dagegen Whitelisting: Dort wird einfach definiert, was erlaubt ist, alles andere ist explizit verboten. Im Falle des Profilbilds müsste man also nur die beiden Bilddateitypen .png und .jpg erlauben, alle anderen möglichen Dateitypen wären dann nicht mehr möglich.
Zudem sollte die Prüfung auf korrekte Dateitypen bereits im Browser des Users vorgenommen werden, sodass potenziell bösartige Dateien gar nicht erst auf den Server geladen werden. Dazu kann ein regulärer Ausdruck verwendet werden, der prüft, ob die Dateiendung den erwarteten Dateitypen entspricht. Als Backup sollte dennoch auf Server Seite eine zusätzliche Prüfung stattfinden. Passt alles, ist diese Prüfung schnell vorbei und beeinträchtigt die Performance nur minimal. Wurde jedoch eine nicht erwartete Datei hochgeladen, wird diese gar nicht erst verarbeitet und stellt somit auch keine Gefahr für den Server dar.
Im Screenshot ist eine einfache Form eines solchen regulären Ausdrucks zu sehen. In diesem Fall sind die Dateitypen .jpg und .png erlaubt. Wichtig: Da .jpg teilweise auch als .jpeg dargestellt wird, ist auch diese Variante erlaubt.
Logins begrenzen
Wie einfach es ist, automatisiert mit einer Webseite zu interagieren, haben wir ja bereits in unserem kleinen Python Skript zur User Enumeration gezeigt. Hat man einen validen User gefunden (was meist nicht schwer ist, weil als Usernamen oft Emailadressen verwendet werden, die sich leicht herausfinden lassen), kann man natürlich auch versuchen, sich in das besagte Konto einzuloggen.
Falls es nur sehr wenige Accounts gibt (etwa einen Admin Account zur Administration der Seite) und diese starke Passwörter verwenden, ist das nicht weiter dramatisch. Da bei Webseiten immer eine gewisse Verzögerung durch die Antwortgeschwindigkeit der Seite gegeben ist, können hier längst nicht so viele Passwörter durchprobiert werden, wie es offline der Fall wäre. Mit einem ausreichend langen Passwort sollte man also auf der sicheren Seite sein.
Anders sieht es aus, wenn es auf der Seite auch eine Möglichkeit zur Registrierung gibt. In diesem Fall kann nicht davon ausgegangen werden, dass alle User starke Passwörter wählen. Das zeigt sich leider auch daran, dass mit schöner Regelmäßigkeit Passwörter wie „123456“ oder „Passwort“ auf der Liste der meist genutzten Passwörter auftauchen. Man kann als Webseiten Betreiber natürlich versuchen, mit einer Passwortrichtlinie einen gewissen Mindeststandard vorzuschreiben, beispielsweise, dass das Passwort mehr als acht Zeichen lang sein und mindestens eine Zahl und ein Sonderzeichen enthalten muss. Allerdings ist das auch ein schmaler Grat zwischen Sicherheit und Usability. Werden zu komplexe Passwörter verlangt, sind die User schnell frustriert, bzw. wird es dann wahrscheinlicher, dass sie Passwörter (die die Kriterien erfüllen) einfach für mehrere Seiten verwenden, was auch nicht im Sinne der IT-Sicherheit ist. Man muss also als Webseiten Betreiber einen Weg finden, seine User selbst dann zu schützen, wenn diese nur ein vergleichsweise schwaches Passwort wählen. Zu diesem Zweck bietet es sich an, die Anzahl möglicher Logins zu begrenzen.
Wer ein Content Management System wie WordPress verwendet, kann diese Aufgabe von einem Plugin wie Wordfence erledigen lassen. Wer dagegen eine selbstprogrammierte Webseite nutzt, muss dieses Verhalten selbst implementieren. Dafür kann beispielsweise die Anzahl an Login Versuchen innerhalb einer bestimmten Zeitspanne gezählt werden. Ist eine bestimmte Anzahl überschritten (z.B. mehr als 10 fehlgeschlagene Login Versuche innerhalb von 10 Minuten) werden weitere Logins unterbunden oder zumindest verlangsamt. Dazu könnte etwa ein Captcha angezeigt werden, das vor jedem weiteren Login gelöst werden muss, oder es wird nach jedem erneutem Login Versuch eine Wartezeit eingeführt, die sich immer weiter erhöht (z.B. nach 11 Login Versuchen 30 Sekunden Pause, nach 12 Versuchen 60 Sekunden Pause usw.).
Bei der Begrenzung der Logins ist es wichtig drauf zu achten, dass der rechtmäßige Account Besitzer jederzeit Zugang zu seinem Account erhalten kann. Würde ein Konto etwa automatisch nach 10 falschen Login Versuchen für eine Stunde gesperrt werden, ohne Möglichkeit diese Sperre zu umgehen, dann könnte ein Angreifer durch wiederholte Logins ganz einfach verhindern, dass rechtmäßige User ihren Account nutzen können.
Es muss also immer eine Möglichkeit geben über die man sich, trotz Sperre, als legitimer User identifizieren kann. Dafür kann eine Variante der 2-Faktor Authentifizierung angewandt werden: Ist das Konto aufgrund vieler falscher Logins blockiert, wird automatisch ein Link an die Mailadresse des Users versandt. Der Angreifer kann dann keine weiteren Logins vornehmen, der Eigentümer des Accounts kann sich aber über den Link, den er per Mail erhalten hat, weiterhin einloggen und sein Konto vollumfänglich nutzen.
https verwenden
Während die meisten anderen der hier vorgestellten Maßnahmen dazu dienen, konkret Ihre Sicherheit als Webseiten Betreiber zu verbessern, geht es bei der Verwendung von https hauptsächlich um die Sicherheit Ihrer User.
Bei normalen http Verbindungen werden nämlich Daten, die der User auf der Seite eingibt, also beispielsweise Username und Passwort, nicht verschlüsselt übertragen. Diese Daten können von einem Angreifer mit einem Sniffer mitgelesen werden.
Um das zu verhindern, sollte alles, was User eingeben können, verschlüsselt werden. Dazu wird ein SSL/TLS Zertifikat benötigt. Ist dieses vorhanden und korrekt, wird in der URL Zeile des Browsers ein kleines Schloss angezeigt, das verdeutlicht, dass die Daten verschlüsselt sind. Ist kein Zertifikat vorhanden, ist das Schloss durchgestrichen und es wird angezeigt, dass die Verbindung nicht sicher ist. Ist zwar ein Zertifikat vorhanden, dieses aber nicht korrekt, erhält der User eine entsprechende Warnung und ihm wird vom Besuch der Seite abgeraten. Dies kann zwar dadurch umgangen werden, dass eine Ausnahme für das Zertifikat hinzugefügt wird, wer Ihrer Seite allerdings nicht vertraut, wird das mit ziemlicher Sicherheit nicht machen. Lange Rede kurzer Sinn: Am meisten Vertrauen erwecken Sie bei den Besuchern Ihrer Seite, wenn Sie ein korrektes Zertifikat verwenden.
Übrigens: Fährt man mit dem Mauszeiger über das Schloss in der Adresszeile, kann man sich anzeigen lassen, wer das Zertifikat für die Webseite ausgestellt hat.
Mittlerweile sieht man allerdings kaum noch http Webseiten. Dies hängt sicherlich auch damit zusammen, dass die Verwendung von https nicht nur der Sicherheit dient, sondern sich auch positiv auf die Suchergebnisse auswirkt. Bzw. wirkt sich die Verwendung von http negativ aus. Bei Google werden unverschlüsselte Seiten etwa deutlich schlechter geranked. Dadurch ergeben sich für Webseiten Betreiber natürlich auch konkrete Umsatz- und Gewinneinbußen, denn der Traffic, den Google auf eine Seite bringt, ist sicherlich nicht zu unterschätzen.
Falls Sie also bisher noch kein SSL/TLS Zertifikat verwenden, sollten Sie dies dringend ändern. Zum einen, weil es der Sicherheit Ihrer User dient, zum anderen aber auch, weil Sie hinsichtlich Traffic und Suchanfragen davon profitieren werden.
Passwörter sicher speichern
In den Anfangszeiten des Internets waren viele Webseiten noch als virtuelle Visitenkarten konzipiert. Auf diesen Seiten fanden sich dann vielleicht Öffnungszeiten einer Firma, allgemeine Informationen oder ähnliches. Interaktionen waren allerdings nicht möglich.
Heute ist das anders. Mit großer Wahrscheinlichkeit gibt es zumindest eine Möglichkeit zur Administration der Seite, sodass etwa Informationen ergänzt oder geändert werden können. Aus diesem Grund sind bei den allermeisten Webseiten Möglichkeiten zum Login bzw. zur Registrierung vorhanden.
Für Webseiten Betreiber ergibt sich dadurch ein Problem: Die Passwörter der User müssen sicher gespeichert werden. Früher wurde Passwörter teilweise einfach im Klartext gespeichert. Eine einfache Lösung, die allerdings absolut keinen Schutz bietet, wenn ein Angreifer erst einmal Zugriff auf die Passwörter erhalten hat (beispielsweise durch eine SQL Injection). In diesem Fall sind sofort alle User Accounts der Seite kompromittiert. Aus diesem Grund ist es heute Standard, Passwörter nicht mehr im Klartext zu speichern, sondern nur noch gehashed. Durch das Anwenden der Hashfunktion MD5 wird aus dem Wort „password“ etwa der Hash „5f4dcc3b5aa765d61d8327deb882cf99“. Verändert man nur einen kleinen Teil des ursprünglichen Wortes (z.B. „password1“) ergibt sich ein völlig anderer Hash (in diesem Fall „7c6a180b36896a0a8c02787eeafb0e4c“). Wer das selbst ausprobieren möchte, kann dazu eine Seite wie Hashgenerator.de verwenden, bei der sich Hashes mittels verschiedener Hashing Algorithmen erzeugen lassen.

Anmerkung: MD5 war in der Vergangenheit weit verbreitet, wird mittlerweile aber nicht mehr als kryptografisch sicher angesehen und sollte in Produktivanwendungen daher keine Verwendung mehr finden. Wir verwenden in diesem Beitrag MD5 zu Testzwecken, weil die erzeugten Hashes verglichen mit anderen Algorithmen recht kurz sind, was Beitrag und Ausgabe des Skripts besser lesbar macht. In tatsächlichen Anwendungen sollten dagegen Hashfunktionen verwendet werden, die kryptografisch sicher sind, aktuell beispielsweise SHA-2. Im Skript kann die Verwendung einer anderen Hashfunktion einfach angepasst werden, dafür muss lediglich MD5 auf eine andere Funktion geändert werden.
Hashfunktionen funktionieren nur in einer Richtung: Aus einem Wort kann also ein Hash erzeugt werden, aus dem Hash lässt sich aber nicht auf das Wort schließen. Die Anwendung vergleicht bei der Anmeldung also nicht, ob die Passwörter übereinstimmen, sondern ob die Hashes übereinstimmen: Der User gibt beim Login sein Passwort ein, dieses wird gehashed und mit dem hinterlegten Passwort Hash des Users verglichen. Stimmen diese überein, war das Passwort korrekt und der Login wird durchgeführt.
Erbeutet ein Angreifer Passwort Hashes, etwa über SQL Injection oder Directory Traversal, kann er diese nicht direkt brechen. Er kann allerdings typische Passwörter hashen und mit den erbeuteten Hashes vergleichen. Stimmen die Hashes überein, kennt er das Passwort. Dieses Verhalten demonstrieren wir mit einem kleinen Python Skript. Den Code finden Sie wie üblich auf unserem GitHub Channel.
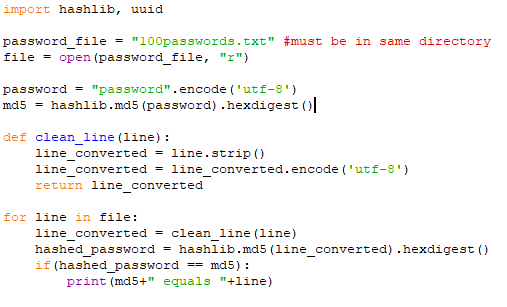
Als Liste möglicher Passwörter verwenden wir die von Daniel Miessler zusammengestellte Liste der 100 gebräuchlichsten Passwörter. Dabei handelt es sich um eine einfache Textdatei, bei der in jeder Zeile ein Passwort steht.
Als Beispiel für einen erbeuteten Password Hash hashen wir das Wort „password“ von dem wir wissen, dass es sich in der Liste befindet. Dazu wird das Wort zunächst mit UTF-8 codiert und anschließend mit MD5 gehashed. In der Schleife hashen wir dann jedes Wort der Liste und vergleichen es mit dem ursprünglichen MD5 Hash. Stimmen die beiden überein, können wir den Klartext des Hashes ausgeben.
In der Realität würde man natürlich keine Liste mit 100 Einträgen verwenden, sondern eine mit mehreren Millionen. Da das Hashen und Vergleichen von speziellen Tools übernommen werden kann, kann auf diese Weise in kurzer Zeit ein beträchtlicher Teil der Passwörter erraten werden. Das bloße Hashen bietet also nur eingeschränkten Schutz.
Als Gegenmaßnahme gegen Angriffe dieser Art kann man Hashes aber auch mit einem Salt versehen. Dies ist ein zusätzlicher Wert, der dem Passwort hinzugefügt wird, bevor die Hashfunktion darauf angewendet wird. Dadurch entsteht also ein komplett neuer Hash. Vereinfach haben wir das weiter oben schon demonstriert, indem „password“ der Wert „1“ hinzugefügt wurde, wodurch ein neuer Hash entstand. In der Realität werden statt einzelnen Zahlen aber längere Zufallswerte verwendet.
Wenn der Angreifer nun in den Besitz der Passwort Hashes gelangt, kann er sie zwar mit bekannten Hashes vergleichen, da er aber nicht weiß, welches Salt verwendet wurde, wird dabei kein Treffer erzielt werden (vorausgesetzt die Hashfunktion ist sicher und es gibt keine Kollisionen). Zu sehen ist das auch in einer Variation unseres Skripts in denen das Wort „password“ dieses Mal vor dem Hashen mit einem zufälligen Wert als Salt angereichert wird. Obwohl „password“ in der Passwort Liste enthalten ist, wird beim anschließenden Vergleich der Hashes kein Treffer erzielt, da sich der Hash durch das Hinzufügen des Salts verändert hat und nicht mit dem ursprünglichen übereinstimmt.
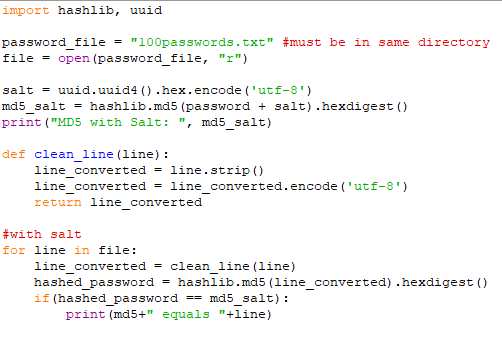
Damit das Ganze funktioniert, muss das Salt natürlich an einer anderen Stelle gespeichert werden als der Hash. Denn wenn man es in der gleichen Datenbank speichert wie den Hash, und der Angreifer Zugriff auf diese Datenbank erlangt, kann er seine Hashes ja ebenfalls mit Salt erstellen und dann funktioniert der Vergleich wieder. Im Idealfall verwendet man für das Salt also eine andere Datenbank als für den Hash.
Außerdem sollte man darauf achten, dass das Salt nicht erraten werden kann. Der Name der eigenen Webseite ist also kein geeignetes Salt. Am besten erzeugt man immer wieder einen genügend langen zufälligen Wert, sodass für jeden User ein anderes Salt verwendet wird. Der Zugriff auf die Hashes ist für den Angreifer dann mehr oder weniger wertlos, solange er nicht auch auf die Datenbank mit den Salts zugreifen kann.
Backups anlegen
Man kann es nicht oft genug sagen: 100 prozentige Sicherheit ist nicht möglich. Wenn man also seine Seite gegen Angreifer absichert, sollte man immer auch Maßnahmen treffen, die sich mit dem Worst Case, also einem erfolgreichen Hack der Seiten, befassen. Dazu gehört insbesondere das Anlegen von Backups.
Stellen Sie sich etwa vor, was passieren würde, wenn einem Onlineshop die Daten der Zahlungsinformationen der Kunden abhanden kommen würden. Abgesehen davon, dass solche sensiblen Daten für die Kunden einiges an Problemen bedeuten würden (unrechtmäßige Bestellungen, Identitätsdiebstahl etc.), ist die Situation auch für den Shop problematisch: Wenn der Angreifer die Daten gelöscht hat und kein Backup existiert, kann nicht mehr nachvollzogen werden, welche Kunden bereits bezahlt haben und welche nicht. Eventuell ließe sich über Bank- und Versandunterlagen rekonstruieren, wer bezahlt hat und wer noch nicht, das wäre aber mit Sicherheit deutlich aufwendiger, als einfach ein Backup einzuspielen und wieder vollen Zugriff auf die Daten zu haben.
Mit dem reinen Anlegen von Backups ist es allerdings nicht getan. Im schlimmsten Fall stellt sich dann nämlich im Ernstfall heraus, dass Daten die wichtig gewesen wären, überhaupt nicht gespeichert wurden. Oder dass der geplante Prozess des Backups Einspielens in der Praxis nicht funktioniert. Aus diesem Grund sollten Backups immer auch regelmäßig getestet werden.
Dabei wird dann einerseits geprüft, ob überhaupt alle Daten gesichert wurden, die für eine erfolgreiche Wiederherstellung erforderlich sind. Zudem wird der Prozess eingeübt. Wenn man ansonsten erst im Ernstfall lernen muss, was in welcher Reihenfolge zu tun ist, ist das Chaos vorprogrammiert. Hat man die nötigen Schritte dagegen schon zigfach geprobt, ist alles nur noch Routine und die neue Webseite schnell wieder im Netz.
Bevor man das Backup allerdings einspielt, sollte man zunächst Beweise für den erfolgten Hack sammeln, da diese ansonsten möglicherweise unrettbar verloren sind. Insbesondere gilt das dann, wenn man eine Versicherung gegen Cyberangriffe abgeschlossen hat. Diese wird im Schadensfall ein Interesse haben zu verifizieren, ob tatsächlich ein Angriff stattgefunden hat, oder ob der Zusammenbruch der Seite möglicherweise selbstverschuldet war. Wenn dann alle Beweise bereits gelöscht sind, ist diese Untersuchung schwierig bis unmöglich, sodass möglicherweise kein Schaden mehr festgestellt werden kann und entsprechend auch nichts von der Versicherung ausbezahlt wird.
Aber auch ohne Versicherung macht es Sinn, die Daten der gehackten Webseite zu sichern und im Nachhinein nachzuvollziehen, wie der Angreifer Zugang zur Seite erlangen konnte. Lag das Problem etwa in einem leicht zu erratenden Admin Passwort begründet, lässt sich das relativ einfach aus der Welt schaffen. Wurde allerdings eine Schwachstelle in Drittanbietersoftware ausgenutzt, die nicht ohne weiteres ausgebessert werden kann, ist eine mögliche Lösung schon komplexer und kann eventuell beinhalten, dass die Software durch eine andere ersetzt werden muss.
Speichern auf Server Seite
Stellen Sie sich vor, Sie betreiben einen Onlineshop. In diesem können Kunden natürlich auch Artikel in den Einkaufswagen legen. Hat der Kunde alles gefunden, was er gesucht hat, kann er zur Kasse gehen und bezahlen. Was wäre nun, wenn der Wert des Einkaufswagens auf Seiten des Kunden gespeichert wäre? Zum Beispiel in einem Cookie? In diesem Fall könnte der Kunde einfach den Preis manipulieren und die Artikel zu einem wesentlich günstigeren Preis erhalten.
Zur Manipulation von Cookies kann ein Cookie Editor verwendet werden, ein Beispiel für einen solchen ist im Screenshot zu sehen:
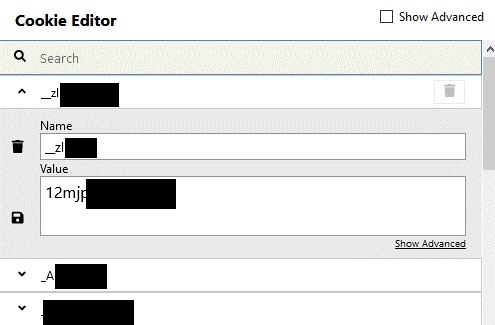
Der Cookie Editor zeigt alle Cookies an, die man von einer Seite erhalten hat sowie deren Wert. Dieser Wert kann ohne Probleme auch verändert werden.
Aus diesem Grund sollten alle wichtigen Informationen (beispielsweise Berechtigungen, Zahlungsinformationen etc.) auf Server Seite gespeichert werden und nicht auf Seiten des Kunden.
Bei bestimmten Informationen, etwa Session IDs, ist es dagegen nötig, sie auf Kunden Seite zu speichern. In diesem Fall sollte man aber darauf achten, dass die entsprechenden Cookies das HTTPonly Flag gesetzt haben. Der Name HTTPonly ist zwar ein wenig verwirrend, sorgt aber dafür, dass Informationen nur über https übertragen werden. Das verhindert unter anderem, dass die Cookie Informationen von einem Skript ausgelesen werden können. Dadurch wird die Übernahme einer Kunden Session durch einen Angreifer (z.B. durch einen XSS Schwachstelle, bei der der ausgeführte JavaScript Code den Wert des Session Cookies an den Angreifer sendet) deutlich erschwert.
Restriktive Berechtigungen
Wie schon erwähnt, sind reine „Visitenkarten Webseiten“ heute kaum noch verbreitet. Dementsprechend stehen die Chancen gut, dass auch Ihre Webseite eine Möglichkeit zum Login bietet. Vielleicht nur für einen einzelnen Administrator, der hin und wieder ein paar Informationen updated, vielleicht für zahllose User die auf verschiedensten Weisen mit der Webseite interagieren können, vielleicht existieren bei Ihrer Webseite auch verschiedene Funktionsrollen, die zusätzliche Berechtigungen haben, aber unterhalb eines Admins stehen.
So oder so, die Berechtigungen die jedem einzelnen Account Typ zugeordnet sind, sollten immer so minimal wie möglich sein. Kann die Zahl der Berechtigungen nicht sinnvoll reduziert werden, sollte die Anzahl der Accounts mit diesen Berechtigungen minimal gehalten werden. Ein Admin etwa muss eben auch in der Lage sein, Veränderungen an der Seite vorzunehmen, daran lässt sich nichts ändern. Allerdings sollten Admin Accounts auch nur an diejenigen vergeben werden, die diese für ihre täglichen Arbeiten auch wirklich benötigen.
Funktionsrollen bieten darüber hinaus die Möglichkeit, einem User Rechte zu geben, die über den normalen User Rechten liegen, aber unterhalb eines Admins. Beispielsweise können User der Gruppe Analyst Traffic Informationen abrufen und auf die Google Analytics Funktionen der Seite zugreifen. User der Gruppe Redakteur können auf diese Infos nicht zugreifen, haben dafür aber die Möglichkeit, Produktbeschreibungen zu verfassen oder zu verändern.
Bei selbstprogrammierten Webseiten können beliebig viele solcher Funktionsrollen angelegt und die Berechtigungen genau auf den jeweiligen Einsatzzweck zugeschnitten werden. Bei Content Management Systemen wie WordPress gibt es dagegen standardmäßig verschiedene Accounts mit vordefinierten Berechtigungen. Ersteres bietet natürlich die Möglichkeit Rechte sehr feingranular zu vergeben, allerdings gibt es auch ein erhöhtes Potenzial für Fehler (etwa, wenn man vergisst einer bestimmten User Gruppe bestimmte Rechte zu entziehen). Vorgegebene Rollen entsprechen dagegen vielleicht nicht zu 100 Prozent dem, was man sich vorgestellt hat, sind aber in der Regel so angelegt, dass es keine gravierenden Sicherheitsprobleme gibt.
Für welche Lösung man sich entscheidet, hängt von diversen Faktoren ab, man sollte aber immer versuchen, Berechtigungen so zu verteilen, dass nur möglichst genau das erledigt werden kann, was für die Erfüllung der Aufgabe nötig ist.
Für den Fall, dass ein User zeitweise, zum Beispiel im Rahmen eines Projekts, erhöhte Rechte benötigt, sollte sichergestellt werden, dass diese Rechte auch nur für den erforderlichen Zeitraum gewährt werden und anschließend wieder entzogen werden. Dadurch wird verhindert, dass User Berechtigungen ansammeln, die sie nicht mehr benötigen.
Fazit
Wenn Sie diese Tipps umsetzen, ist Ihre Webseite gegen typische Angriffe schon recht gut abgesichert. Zu beachten ist allerdings, dass die Sicherheitsmechanismen auch erhalten bleiben, wenn später Änderungen an der Seite vorgenommen werden. Immer mehr Software wird heute agil entwickelt. Das bedeutet, im Gegensatz zu früher arbeitet man nicht mehr monatelang an einem großen Update und hat danach wieder ein paar Monate seine Ruhe, sondern es werden kontinuierlich Updates und neue Funktionalitäten implementiert. Diese im Nachhinein auf Sicherheit zu überprüfen, kann ein extrem komplexes Unterfangen sein. Am besten arbeitet man deswegen nach dem Security by Design Prinzip. Bei diesem Softwareentwicklungsprinzip sind Sicherheitsanforderungen von Anfang an Teil der Entwicklung, wodurch Anwendungen typischerweise deutlich sicherer werden als solche, bei denen man versucht sie nachträglich noch irgendwie sicher zu bekommen.